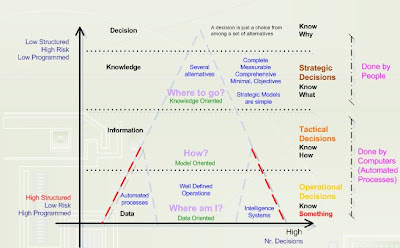
Operational decisions involve day to day operations, dealing with problems that often become well known, such as how many units of a product to stock, or what employee to assign to what task. These decisions usually are repeated quite often.
At the other extreme, strategic decisions involve the long-range plan of the organization. Strategic decisions occur much less often then operational decisions, but affect the entire firm, may involve large sums of money, and there is inherently more risk involved in making them.
Tactical decisions are usually required more often than strategic decisions, but not as often as operational decisions. Middle level managers usually have more discretion than operational decision makers, but are constrained by strategic plans.

Strategic Level
Organizational vision and mission
Organizational policies
Target markets
Long-range goals
Future-oriented
Tactical Level
Middle management
Mid-range goals
Effective resource allocation
Budgeting, for example.
Operational Level
First line management
Short-range goals
Day to day activities (efficiency)
There are persons that are so focused in the goals and gives so high importance to the methodologies that a problem leaves of being a problem.
The classic decision-data pyramid will be transformed in a losangle, because the solution to resolve a problem will be repeated and is converted in an automated process, as you can see in the following picture:
Organizational vision and mission
Organizational policies
Target markets
Long-range goals
Future-oriented
Tactical Level
Middle management
Mid-range goals
Effective resource allocation
Budgeting, for example.
Operational Level
First line management
Short-range goals
Day to day activities (efficiency)
There are persons that are so focused in the goals and gives so high importance to the methodologies that a problem leaves of being a problem.
The classic decision-data pyramid will be transformed in a losangle, because the solution to resolve a problem will be repeated and is converted in an automated process, as you can see in the following picture:

Following Gorry and Scott Morton approach, the degree of structure for a problem changes as decision makers learn more about problems.
And each problem could be classified from different levels:

This picture demonstrates well the problem decision, and following my teacher homewrok request I will describe in the next post, the most important level - management level, tasks and sub-tasks.

















{kind=link}
{kind=link}
{kind=link}